
This is the beginning of the “Git – Simplified” course which will explain, describe and walk you through the most basic knowledge of “Git” to the most advanced “Git”, or as I would say “from zero to hero”.
Table of Contents
🎤 Webinar recording (Hebrew)
You can find the presentation (ppt file) at this link . The recorded session of the webinar is live! you can view it here:
🛠️ Prerequisites
This tutorial requires knowledge in basic terminal\cmd usage, such as navigating between folders (cd command) and other basic commands.
In this guide we will use the following:
- VSCode – Microsoft source code editor. In other words called “Visual Studio Code”, pay attention as it is not Visual Studio! They are two different code editors. Also make sure to install the Git Graph extension on VSCode.
- Git Bash – The Git bash is the main utility we will use in order to manage git.
Make sure to configure your bash before starting up with the tutorial:
If you are a developer, you should be fine with the rest of this guide.
🙄 What is Git?
“Git tracks the changes you make to files, so you have a record of what has been done, and you can revert to specific versions should you ever need to. Git also makes collaboration easier, allowing changes by multiple people to all be merged into one source”
What is Git and Why Should You Use It? Free Intro to Git Guide
And if I still didn’t get it?
Git is a time machine for all of the files under your directory!
It simply creates a history of how your directory looks like, that you can move between its snapshots. A snapshot is a point in time.
🧰 Git architecture
👄 Terminology
Before we get started we should know the terminology used within git:
- Repository – A “place” where all of your code\files history is stored. You can always go back to different “times” (commits) of your code and see your code at a specific point in time.
A repository contains a list of “commits”, branches, and tags.
In fact, when setting up git, the repository is the “.git” folder. You usually don’t touch this folder and it is managed through git bash or other “git” friendly utilities.
- Commit – A “snapshot” of your project files in a specific time. This snapshot only contains the “diff” of the files that were changed. This allows your repository to be smaller as it only contains what was changed in your code.
- Branch – A “workspace” your code lies on within the repository, where you can do whatever you like without harming your main code (“master”) branch. We will explain branches later on. But you can think of a branch as a “copy” of your code where you can do whatever you want in, and later on push it back to your main code (“master” branch).
Git has two ways of running:
- On local machine only – manage your code\files locally.
- Local + remote – manage your code locally and in-sync with a remote repository. This is mainly used. The remote repository can be GitHub\GitLab\BitBucket\etc.
📦 Local repository
Starting up a git project always begins with a local repository. Git does not require a server at all, and can run entirely on your computer. In fact, you can work entirely with your local repository and just open up a remote repository later, then push those changes.
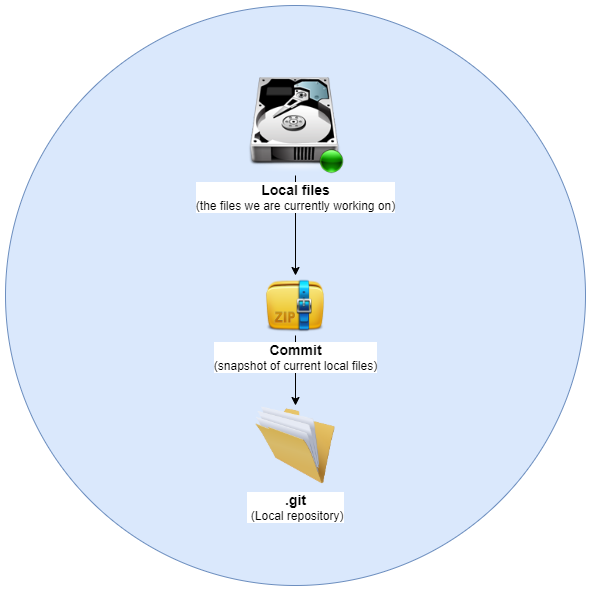
Setting up a local git repository
Before we can start up. Please make sure to install git bash:
💡 In this guide we will only use git bash, GUI utils like “Source tree” won’t be used, I would highly recommend anyone to avoid “GUI” tools for this guide, as it is limited, though generally you can use them at any of your projects as they are highly useful, specially for solving conflicts and showing diffs.
After downloading and installing “Git Bash”, we are ready to start.
Setting up the local repo
- Open up a directory called “git-training”.
- Open up a terminal\cmd\git bash > cd into “git-training”. If you installed git bash with it’s defaults you can simply right click the folder > “Git Bash Here”
- Type the command:
git init. - Now if you look carefully you will see a new folder was created called “.git”. This is your local git repository. No need to touch this folder!
So, setting up a local repository is simple as a command. Don’t you think?
Your first commit!
So we finally setup our git repository. We are ready to add our first commit.
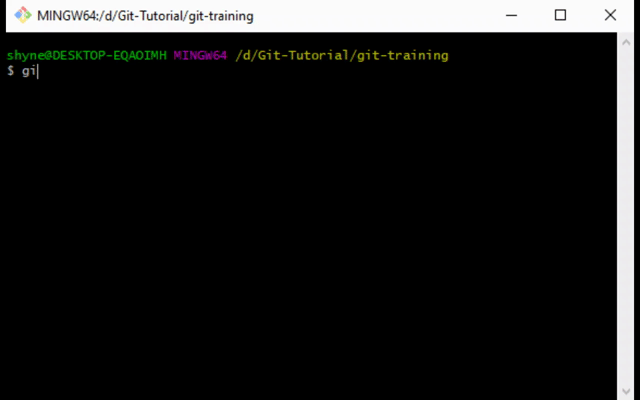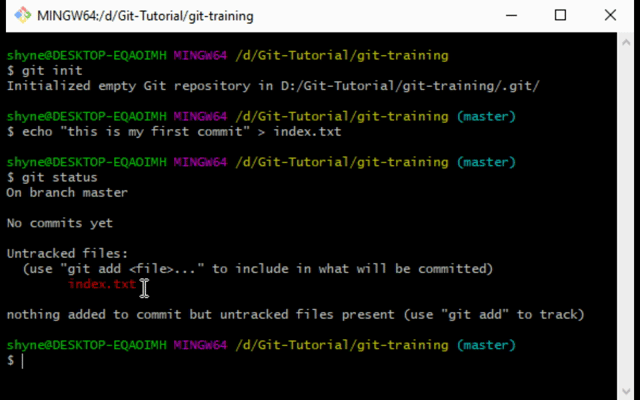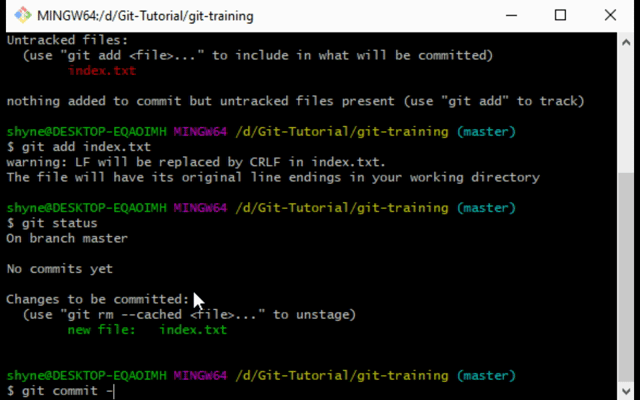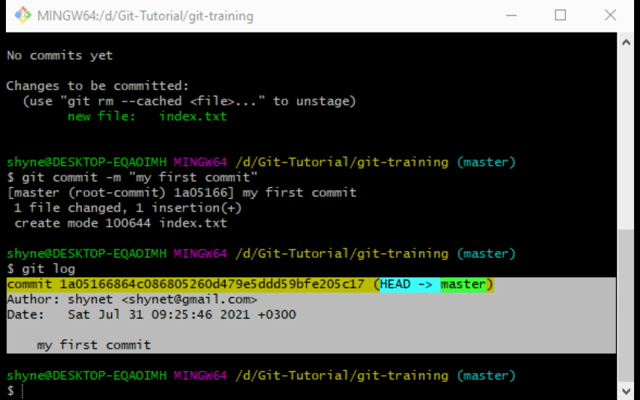
- Create a simple file called
index.txt. - Open up VSCode\any other text editor. And add the line: “this is my first commit”
- Save your file.
- Now open up git bash again and type:
git status:
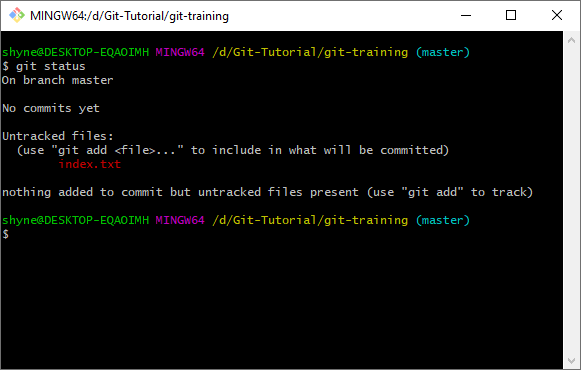
- You will see your file there in red text. This means that our file is “untracked”. We must “track” it by adding it to the staging area before committing.
What is the “staging area”?
The staging area is the place where we setup our workspace before actually committing the code (i.e, taking a snapshot of it). This is important as it tells git we actually want this file to be included in the commit, which will result in it to be included in our repository.
Think of it as a way of telling git “Hey, I want this next commit to include the following files”.
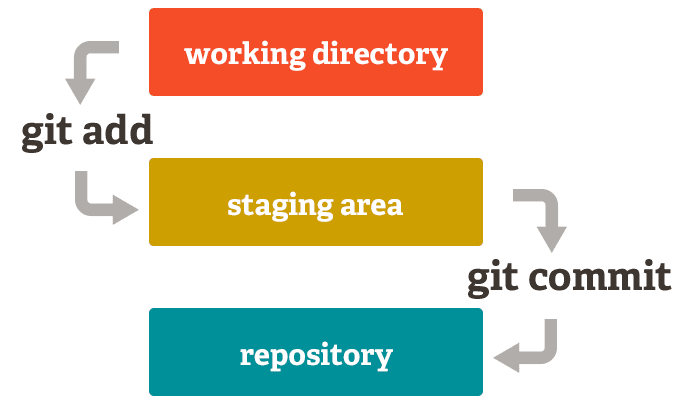
Now let’s add this file to our staging area and create our first commit!
- Type the following:
git add index.txt. This will result in a green text saying our file is now tracked before the commit:
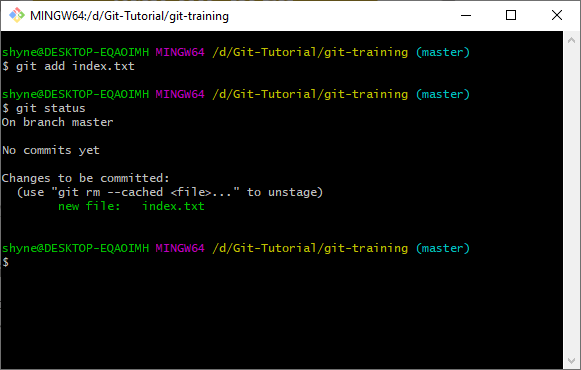
- Now lets commit our code:
git commit -m "my first commit". - In order to check if our commit suicided we can simply type
git statusagain and see that we won’t have any files there anymore. This means our staging area is clean. - You can also type in
git logto see all of the repository commits. There you will be see our newly created commit!
Yay! You have just created your first commit!
But what the hell we typed? Well, git commit means we want to create a commit, and -m means the commit message will be "my first commit".
Every-time we create a commit, we want the commit to have description so we can identify it later on.
Here is an animated gif which summaries what we did:
echo "this is my first commit" > index.txt, this command will actually create our file with the contents already in. We used the git log command in order to show our repository history. This allows us to see that our commit was added to the repository.The .gitignore file
There are times when you don’t want some files\folders to be included in your repository. Adding files to our repository can increase our repository size and impact the overall performance of our git repository when syncing.
For example: You are a game development company and building\compiling your game will result in a binary (executable file) that takes 2.3GB . That’s a lot! Because the code is already there and you can compile it for yourself and reach that same exact binary, you don’t need to include it in your repository.
An example of files you don’t want your repository to include:
- A code-compiled directory (dist\out) – In git we don’t store any “generated” binaries or compiled code as the developer should by definition build the code.
- A temp directory\files – Other developers won’t need your temp files. These temp files are usually generated on your code compilation, or by your IDE (PyCharm, VSCode, others).
- Development platform libraries – For example, on node you have the “node_modules” directory, which contains all of the related modules your project relies on. You can simply install them by using
npm install. Adding them to your repository will severely impact your repository performance and is just a bad practise!
So what do we do? Simple! create a .gitignore file. This file will contain all of the directories\files we want to be ignored.
Let’s do this!
- Create a
.gitignorefile on ourgit-trainingdirectory. Make sure it has no.txtending! I would highly recommend you to create this file like this:echo "" > .gitignore. This will make sure your Windows\Linux\Mac won’t add any unexpected endings. - Create a directory called
tmpand inside create a file calledtest.txt. - Now go back to your terminal and type:
git status:
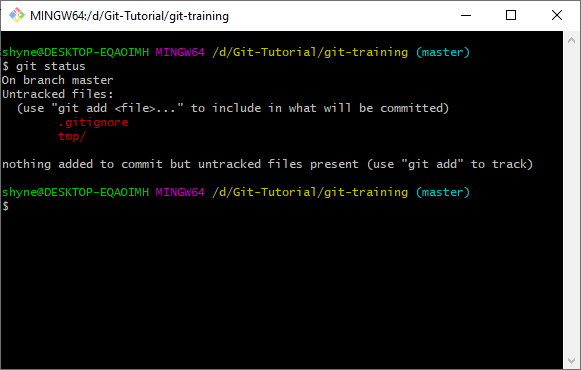
- Now on your
.gitignorefile add the following line:tmpand save! - Type
git statusand see what happens:
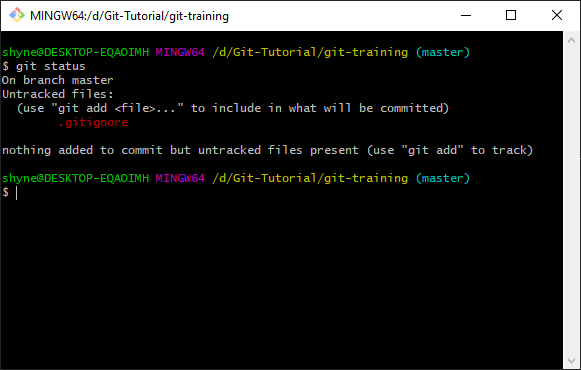
- Now we can’t add the tmp directory to our repository as it is being ignored!
Tips for .gitignore
When creating your project make sure to always look for pre-existing .gitignore files. There are many of them on GitHub. You can find .gitignore for:
- Python projects
- Node projects
- Unity projects
- C# projects
- and more…
For example if you are a Unity game developer, simply look for “unity .gitignore”. Usually the first result will do the job:
https://github.com/github/gitignore/blob/main/Unity.gitignore
👬 Cloning a repository
What does clone mean?
Cloning a repository means we want to “copy” a remote repository (we will explain later on what is a remote repository, but think of it as a local repository sitting on a server for now).
Copying a repository actually means:
- Copying all of the commits
- Copying all of the branches (explained in the next chapter)
- Other git related data
In others words: Taking a remote repository and cloning it to our computer, making a duplicated local repository version of that repository.
How do I clone a repository?
Cloning a repository is easy, let’s have an example:
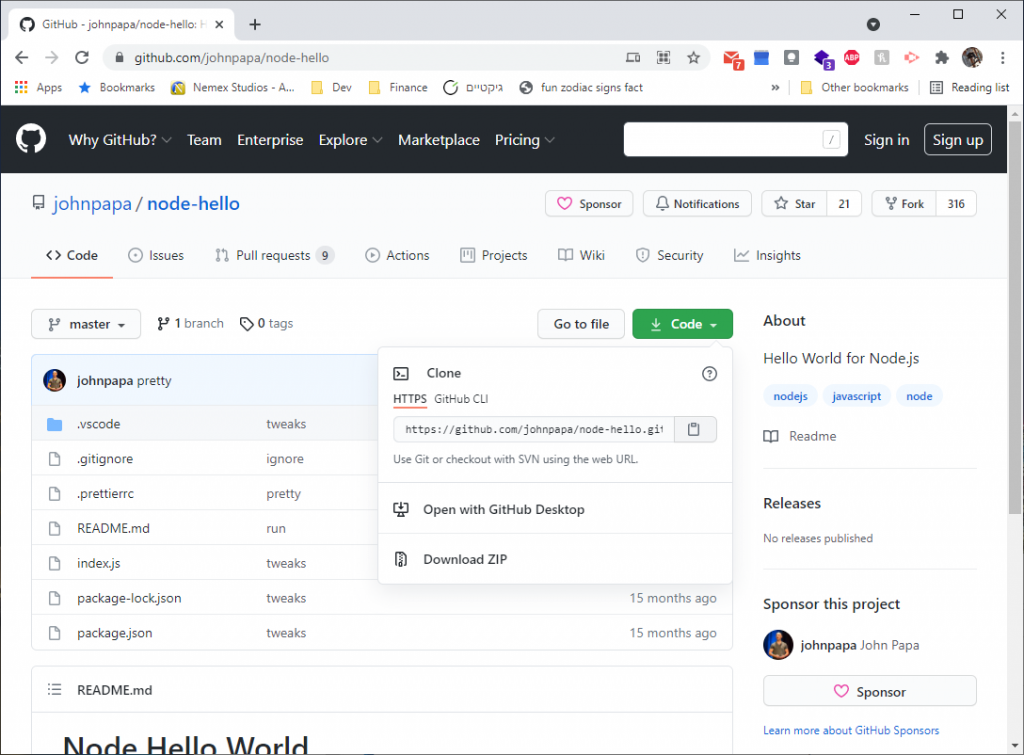
- Open up johnpapa/hello-node:
GitHub – johnpapa/node-hello: Hello World for Node.js
- Click on “Code” (formely “Clone” button) and click on the “copy to clipboard (📋)” button:
- Now open up “git bash” in any directory you want and type
git clone, make a space and paste the url. You should end-up with something like this:git clone https://github.com/johnpapa/node-hello.git - Press enter and you should have this repository cloned in no time!